In the early 2000s, Google faced a scaling challenge. It crawled billions of web pages, generating terabytes of data that were stored and needed to be accessed fast. To manage this data, Google needed a lot of machines to store that data on a distributed system. Traditional file systems were not designed to handle data at this scale.
To overcome these limitations, Google developed Google File System (GFS), a distributed file system to support large-scale data-intensive applications. GFS was created to achieve high performance, scalability, and availability across thousands of machines. New design choices were introduced for large-scale systems. GFS clusters consist of thousands of inexpensive commodity machines, so machine failures are expected. GFS primarily focuses on multi-gigabyte files containing massive collections of documents and data. GFS adopts larger block sizes compared to traditional file systems and optimizes its architecture for large datasets.
Design Overview
One of the primary assumptions of designing GFS was that most files were not frequently modified. Rather than overwriting existing data, applications usually appended new data to files. Once files were written, applications primarily read sequentially for large-scale data analysis. GFS was optimized for append operations and sequential reads instead of random writes or random reads. It also supports appends from multiple clients. Many Google applications used files as producer-consumer queues where hundreds of machines simultaneously appended data to the same file.
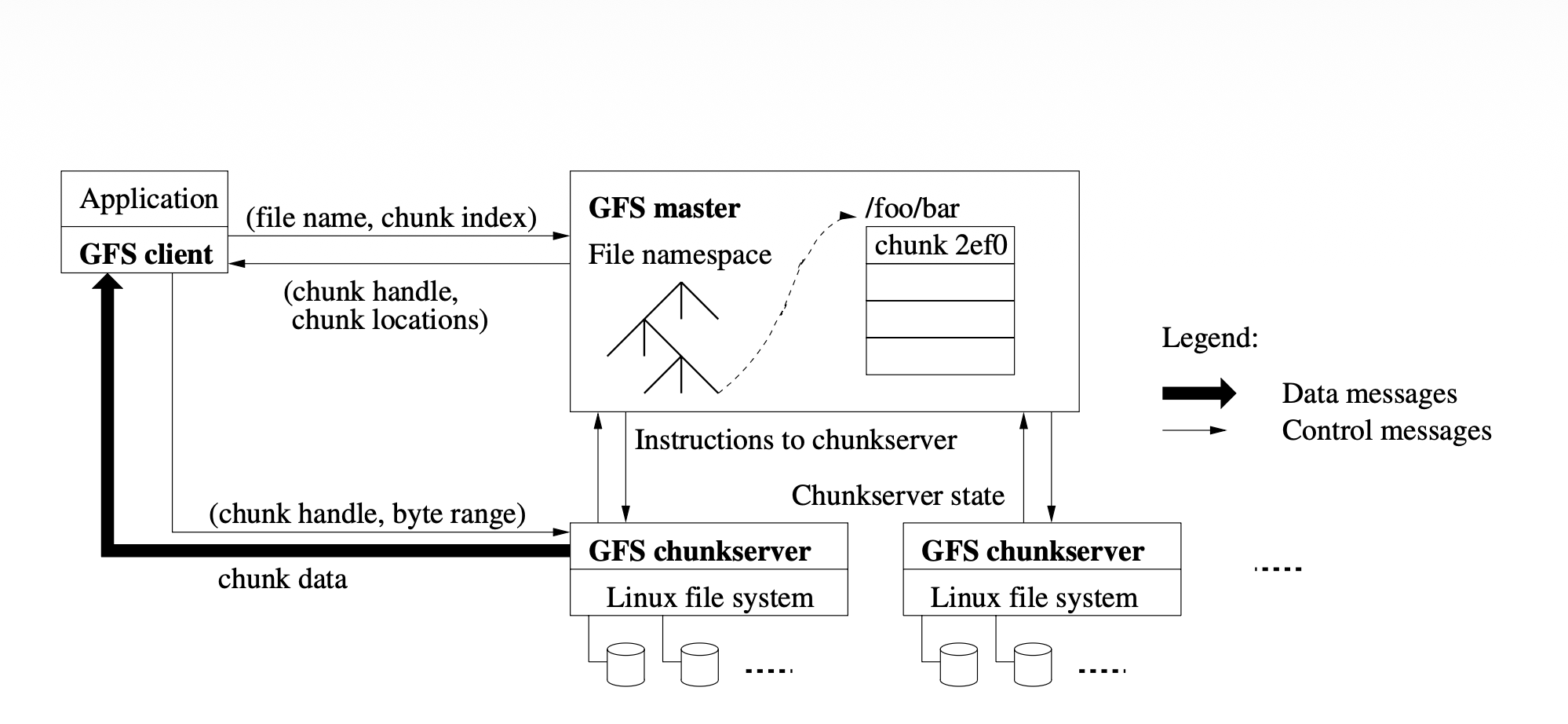
Figure 1: High-level architecture of Google File System (GFS)
The architecture of GFS consists of two main components: a single master server and multiple chunkservers. Files are divided into globally identified fixed-size chunks and replicated across chunkservers. The master server manages all metadata within the system, including the file namespace, access permissions, file-to-chunk mappings, and chunk replica locations. It also controls background tasks such as chunk replication and load balancing. Clients communicate with the master only for metadata-related operations, while actual file data transfer occurs directly between clients and chunkservers. This design prevents the master from becoming a performance bottleneck. GFS also uses a single master as it simplifies metadata management. During a read operation, the client first contacts the master to obtain the chunk handle and replica locations for the requested file. After receiving this metadata, the client communicates directly with the appropriate chunkserver to read the data. One of the other design choices in GFS is its large chunk size (like a 64 MB chunk size). Large chunks reduce communication with the master, lower metadata overhead, improve sequential read and write performance, and allow clients to maintain persistent TCP connections with chunkservers.
The master server maintains information about file and chunk namespace, file-to-chunk mappings, and chunk replica locations. Most metadata is stored in memory for faster access, while metadata updates are recorded in an operation log which has checkpoints when it grows beyond a certain size. It can recover by loading checkpoints from local disk and replaying only the logs after checkpoints. The master does not store chunk replica locations permanently. Instead, chunkservers periodically send heartbeat messages containing the current status and chunk information.
GFS follows a relaxed consistency model designed specifically for large distributed applications. A write operation becomes consistent but undefined when multiple clients write concurrently to the same file region or when retries occur after partial failures. In this case, all replicas eventually contain the same data, making the file region consistent, but the exact contents are unpredictable because the writes may be interleaved or overwritten in different ways. As a result, every client sees identical data, but that data may not match what any single client originally intended to write.
For example, if Client A writes "AAAA" and Client B writes "BBBB" at the same offset simultaneously, the final stored data could become a mixed result like "AABBBB" or "BBBBAA". All replicas will store the same final value, but the exact output is undefined.
The table below summarizes how GFS guarantees consistency depending on the type of mutation and whether it succeeds or fails.
| Operation | Scenario | Result |
|---|---|---|
| Write | Serial | Defined — all replicas contain exactly what the client wrote, in the expected order |
| Write | Concurrent | Consistent but undefined — all replicas agree on the same bytes, but the content may be an unpredictable mix of interleaved writes from multiple clients |
| Record Append | Serial | Defined — the record is atomically appended at a GFS-chosen offset; every replica stores identical data |
| Record Append | Concurrent | Consistent but may have duplicates — each record appears fully and uncorrupted, but a retry after failure may cause the same record to appear more than once |
| Any | Failure | Inconsistent — replicas may diverge; GFS detects corruption via checksums, re-replicates from a healthy copy, and never returns corrupted data as valid |
GFS inserts padding to avoid splitting records across chunks, making concurrent appends simpler, faster, and atomic. Rather than enforcing strict correctness at the storage layer, GFS keeps the system simple and fast by allowing duplicates, padding, and relaxed consistency — leaving applications to handle correctness through append-only design, checkpoints, checksums, and unique record IDs.
GFS guarantees data is not corrupted, but with concurrent writes/appends, the exact order and duplication are not guaranteed. It guarantees that successful writes are correct and replicas stay consistent. On failure, the system never returns corrupted data as if it were valid.
System Interactions and Master Operations
The design of the Google File System minimizes the involvement of the master server in regular operations to avoid bottlenecks. Most data transfer occurs directly between clients and chunkservers, while the master manages the metadata. GFS uses a lease mechanism to maintain a consistent mutation across chunk replicas. To achieve this, the master grants a lease to one replica called the primary replica. The primary determines the serial order of mutations and coordinates updates across multiple replicas.
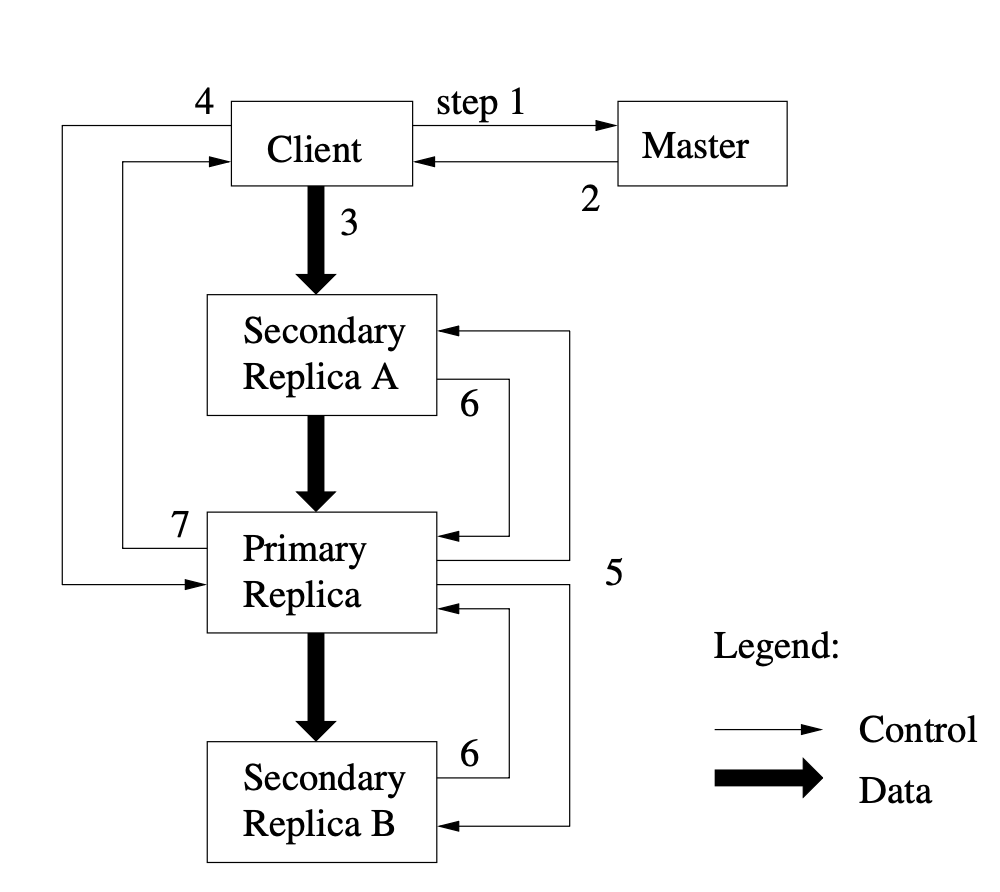
Figure 2: Interaction between client, master, and chunkservers during a write operation
During a write operation, the interaction between the client, master, and chunkservers follows several steps. First, the client asks the master which chunkserver currently holds the lease for a chunk and where the other replicas are located. The master responds with the identity of the primary replica and secondary replicas. The client then pushes the data to all replicas before sending a write request to the primary. The primary assigns serial numbers to mutations, applies the mutation locally, and forwards the request to secondary replicas. Each secondary replica applies the mutation in the same order and acknowledges completion. Finally, the primary sends the result back to the client.
GFS also separates the flow of data from the flow of control to improve network efficiency. Instead of sending data separately to every replica, data is transferred through a pipeline of chunkservers. Each chunkserver forwards data to the nearest replica in the network topology, reducing network bottlenecks and utilizing bandwidth.
Another major feature of GFS is the atomic record append operation. The client does not specify the exact offset for writing data. Instead, the client simply requests GFS to append the record to the end of the file, and the system itself chooses the correct offset. This is especially useful in distributed systems where many machines write to the same file simultaneously, such as log collection or large-scale data processing. The operation is called atomic because each record is appended completely without being mixed or overlapped with another client's data.
For example, suppose three machines want to append "Error1", "Error2", and "Error3" to the same log file at the same time. Instead of each machine calculating where to write, GFS automatically places each record safely at the end of the file. The final file may contain the records in any order, such as "Error2", "Error1", "Error3", but each record will appear fully and correctly without corruption or overlap.
For namespace management, GFS uses a locking mechanism to support concurrent operations. Each node in the namespace tree has associated read-write locks. Operations acquire locks in a consistent order to avoid deadlocks while allowing multiple operations to execute concurrently when possible.
A directory is not stored as a single mutable object that contains a list of filenames. Instead, the namespace is treated like a lookup table where each full path (for example /home/user/foo) is an independent entry mapped to metadata. Because of this design, when a new file is created, GFS does not modify a shared directory structure; it simply adds a new pathname entry. This means other operations that are reading the existing namespace can continue to see the old entries unchanged while the new file is being added. To ensure safety, operations still take a read lock on parent directories so they are not deleted or renamed during the process, but they do not require a write lock on the directory. As a result, readers can continue accessing the existing file list while new files are being created concurrently, and each file creation only needs an exclusive lock on its filename to avoid conflicts.
For example, suppose a directory /projects already contains files like /projects/report.txt and /projects/data.csv. While one client is reading these existing files, another client creates a new file called /projects/log.txt. In GFS, the directory is not updated as one large shared object containing all filenames. Instead, the new pathname /projects/log.txt is simply added as a separate namespace entry. Because of this, the client reading /projects/report.txt and /projects/data.csv can continue its operation without interruption while the new file is being created. GFS only takes a read lock on the parent directory /projects to ensure it is not renamed or deleted during the operation, while an exclusive lock is applied only to /projects/log.txt to prevent conflicts if another client tries to create the same file simultaneously. In a traditional file system, creating a new file usually requires modifying the shared directory structure itself, which may block other operations accessing the directory until the update is completed.
Replica placement is another critical responsibility of the master. Since GFS clusters span many machines and racks, replicas are distributed across different racks to ensure data remains available even if an entire rack fails due to switch or power issues. The master also handles chunk creation, re-replication, and rebalancing. New replicas are placed on chunkservers with lower disk utilization and distributed across racks for fault tolerance. When replicas are lost because of machine failures or corruption, the master quickly initiates re-replication to restore the desired replication factor.
Fault Tolerance
To achieve high availability, GFS uses fast recovery and chunk replication. Both masters and chunkservers can restart within seconds after a crash, and clients automatically reconnect and retry requests. Every chunk is replicated across multiple chunkservers, usually three copies by default, so data remains available even if a machine fails. The master continuously checks replica health and recreates missing or corrupted replicas when necessary. The master itself is also replicated through operation logs and checkpoints stored on multiple machines. In addition, GFS uses "shadow masters" that provide read-only access when the primary master is unavailable.
Data integrity is maintained using checksums. Each chunk is divided into 64 KB blocks, and every block has a checksum stored separately from the data. Before returning data to a client, chunkservers verify the checksum to detect corruption. If corruption is found, the system reads data from another healthy replica and replaces the damaged copy automatically. Background scanning during idle periods also helps detect corruption in rarely accessed chunks.
Conclusion
Google evaluated GFS using both experimental and production clusters. In benchmark tests, read throughput scaled efficiently as more clients were added, reaching aggregate read speeds close to network limits. Writes were slower because every write had to be replicated to multiple chunkservers, but the system still delivered strong aggregate throughput. Record appends, which are heavily used in Google workloads, also performed efficiently under concurrent access.
Real-world clusters stored tens to hundreds of terabytes of data across hundreds of chunkservers while maintaining relatively small master metadata sizes. Recovery times were fast; even after losing chunkservers containing hundreds of gigabytes of data, the system restored replicas within minutes.
The workload analysis showed that production workloads are dominated by large sequential reads and append operations rather than random overwrites. This observation strongly influenced the design of GFS. Most requests sent to the master involved locating chunks or identifying lease holders, and the master itself did not become a bottleneck.
Original Paper: The Google File System (2003)